CLiC is a web-based application from the University of Birmingham that can be used to search and explore literary texts, providing the user with insight into language used and perception of characters within. CLiC is both used as a tool to support active research and an outreach tool, for example workshops are run with pre-university students so they can get a taste for what they might be doing if they entered the field. More information can be found on the CLiC website.
The CLiC project was originally developed in-house, however a series of projects by Shuttle Thread have transformed it into the current CLiC 2.0. Initial work was focused on immediate improvements of the existing system to improve performance, and later work re-working the entire system to produce CLiC 2.0, a complete rewrite of the CLiC server-side and a reworked UI.
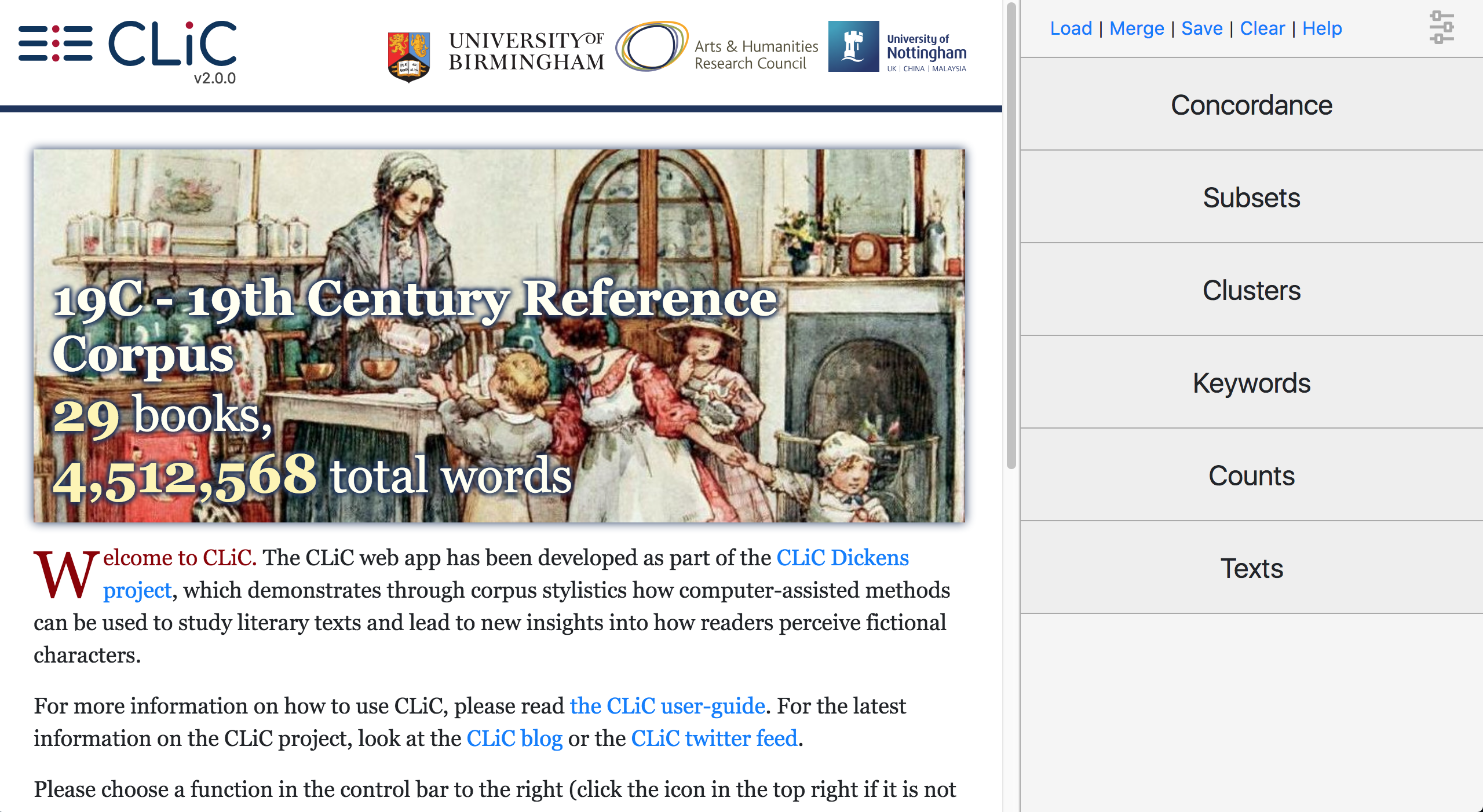
The new CLiC 2.0 UI
Get a feel for the success for the new version by having a look at the CLiC blog or the CLiC twitter feed.
Some of the highlights from a technical point of view are:
Performance improvements on existing codebase
The first issue to solve with CLiC was performance, and dramatic performance improvements were delivered by reworking the original code-base, optimising poorly-performing algorithms and adding caches where appropriate, whilst not altering the overall structure of the application.
Future-proof PostgreSQL schema design
Shuttle Thread switched CLiC 2.0 to a PostgreSQL-based backend, which allowed many problems to be solved with the existing data representation. The schema now has an extensible language of region tags, which will allow CLiC to work with any number of text regions in the future without any schema changes.
Whilst PostgreSQL has many text searching features, CLiC uses it's own tokenisation tables to allow maximum control of search methods. Unlike traditional search applications, CLiC cannot utilise lossy techniques such as stemming, stop words, etc.
Queries that replicate existing functionality of CLiC have been heavily optimised to ensure that CLiC 2.0 can provide fast answers.
CLiC UI redesign
As part of CLiC 2.0 the UI was redesigned with a consistent "control panel" UI across all search modes, each sharing widgets where appropriate. To make full use of the speed of CLiC 2.0, search results update as soon as changes to the selection have been made, making experimentation within CLiC a much more fluid process.
All URLs in CLiC are persistent, so any research referencing CLiC can include a repeatable search simply by linking to it.
Explicit definition of methods
A big part of what CLiC offers is it's text segmentation; all texts have been pre-processed by CLiC, dividing up into words, sentences, paragraphs, speech, etc. With CLiC 2.0 both tokenisation and text segmentation were completely rewritten, and using doctests I worked together with department staff to create reference documentation for all methods that is tested against code. This now can be referenced in research to describe the internals of CLiC.
CLiC API
As each part of the original CLiC was worked on, the API offered by the CLiC server was simplified and standardised, and HTML generated by the server was replaced with further API calls. This has allowed 2 things to happen.
Firstly it allowed parts of CLiC to be replaced independently, integration tests could be run on both old and new implementations, and the UI can be developed independently of the CLiC API.
Secondly, it allowed access to CLiC's segmented text from environments such as R, for which there is now an official client, clicclient. More specialised tools and experiments can use the data from CLiC without having to be integrated into the CLiC UI.
Open source development
All of the CLiC source is available online via. GitHub.